Live tracking
Day 4 update: 27-Sep-2015
Day 3 update: 26-Sep-2015
Day 2 update: 25-Sep-2015
Day 1 update: 24-Sep-2015
Design changes
Telemetry schedule
Photos
David VE3KCL launched his sixth balloon flight S-6 on 24-Sep-2015 at about 17:00 UT. Like the former flights, this one also used a special U3 firmware version on an Arduino Nano board, with QRP Labs Si5351A Synthesiser. Two foil "party" balloons are used, filled with hydrogen. The design changes relative to the former S-4 flight are listed below.
Live tracking
The map below is updated automatically with the latest received position. During the balloon's night, there is insufficient power to run the transmitter, so no updates are received until the following morning.
Day 4 update: 27-Sep-2015
Could S-6 have made a miraculous recovery from its rapid descent in stormy weather yesterday, and still be flying? After all, at the last report yesterday, it was at an altitude of 3,300m, which does still leave some height for a recovery. Since the evidence indicates that the power ran out before landing in the sea, and we could not track it down to a lower altitude - that also leaves some faint hope that S-6 might have recovered.
Miraculously, today at 13:18 UT the following lonely WSPR telemetry report was received by AF7HL in Seattle, US:
![]()
The telemetry decodes to:
| Subsquare | "NR" |
| Altitude | 6,720m |
| Temperature | +23C |
| Battery voltage | 3.44V |
| Groundspeed | 54 knots |
| GPS status | 0 |
| Satellite status | 0 |
Since we only have the telemetry WSPR message (the second transmission), and not any reception report of the standard WSPR message (the first transmission), we do not know the first 4 characters of the Maidenhead locator. So nothing definite can be said of the balloon's current position. Click the below image to see the NOAA Hysplit model prediction, starting at the last known position on 27-Sep-2015 17:30 UT. According to this, S-6 would probably be somewhere near Iceland. The X-ray solar storm (see picture, below right) could cause poor propagation conditions that could help account for the reception of only a single transmission from the balloon.


We also have to consider the possibility of a false WSPR decode which just so happens to have occurred on the right band and time. False WSPR decodes DO occur, although WSPR's forward error correction techniques are strong, nothing can be perfect. But this is unlikely to be a false decode, for the following reasons:
1) The altitude is in the correct range. We expect it in the range 0 to 8,000m (maximum reportable in the telemetry is 21,340)
2) The temperature is in a reasonable range - it would have been close to midday near Iceland, and this kind of temperature is not inconsistent with what we have seen, or what would be reasonably expected at the altitude and time of day. The telemetry can report -50 to +39C. If the report had shown a temperature below zero, or somewhat hotter, then it would not have been so reasonable.
3) The battery voltage is also in a reasonable range. The S-6 flight has reported battery voltages in the range 3.1 to 3.9V. The telemetry can report the range 3.0 to 4.95V.
4) The GPS status and satellite status are both zero, which is also reasonable. Remember that the satellite status is 1 if at least 8 satellites are being tracked. The GPS status is 1 if the $GPRMC validity flag is set to "A". Some combinations of these flags would not be possible, e.g. if 8 satellites were being tracked, it would not be possible for the validity flag to be 0. In practice, we always observed both flags are 1, or on a cycle where GPS doesn't fix, they are both 0 (as here).
Nothing can be said about the Maidenhead subsquare, which is useless information by itself. The above four pieces of data were within reasonable expected ranges (within the maximum available range for each parameter). I estimate the probability of a set of all four pieces of data occurring within reasonable ranges, RANDOMLY, would be less than 4%. Put another way, there could be said to be a 96% chance that the data is a valid spot. The reception signal to noise ratio of -28dB is also consistent with the very weak signal from the balloon, and a long way from Seattle, USA.
On the other hand - this spot is at 13:18 UT. This is wrong! According the transmission schedule, the 13:18 transmission should be the normal WSPR transmission. The 13:20 transmission would be the telemetry. We could speculate that perhaps since the GPS is showing 0 status, it means it had not managed to acquire a lock which could be used to correct the time. In that case, perhaps the real time clock on the balloon was set to an invalid time, but still starting at the right point to enable WSPR copy.
At such high latitudes (near Iceland) the sun angle would be much lower in the sky. Therefore not so much sunlight hits the solar cells. The spot was received at midday (Iceland), at which time the power from the solar cells would be maximum. In the above image you can also see an X-ray solar storm, which could have affected propagation, and all the more so given the high latitudes the balloon is probably flying in. It could explain why only a single spot was received on 27th September - a combination of limited transmitting time due to poor power availability, and poor propagation. It also makes that spot more likely to be genuine. The balloon cannot be transmitting during darkness, and it is most likely to have been transmitting only at most for a few hours. The spot was received at what would be the most likely transmission time during that day.
I decided to check the WSPRnet data for the whole of September to date, to see how common "False" decodes are. In the analysis a "False decode" is one which has a callsign matching the telemetry format adopted for the VE3KCL balloon flights. Which means: the 1st callsign character is "0" or "Q". For the purposes of the analysis I am assuming that the AF7HL spot of S-6 is genuine. This is the summary of the investigation:
| 6,424,266 | Total WSPR spots |
| 107 | "False" decodes (callsigns start "0" or "Q") |
| 32 | of the 107 "False" decodes were on 30m band |
| 5 | of the 107 have "sensible" data, applying the 4 conditions I mentioned above |
| 2 | of those 5 occur between 0900 UT and 2100 UT (S-6 cannot transmit at night!) |
| 7 | of the 107 are on telemetry channel 1 (matching S-6 balloon) |
The number of "False" decodes occurring on 30m, on telemetry channel 1, with sensible data, and in the time range 09:00 UT to 21:00 UT, is ZERO. Note that the percentage of these random false decodes generating sensible balloon telemetry data according to my conditions 1 to 4 above, is 4.7%. This corresponds well (given the sample size) with my prediction above (I said the probability of "sensible" data occurring randomly was below 4%).
I found another interesting event. At 16:08 UT on 25-Sep-2015, S-6 was reported by 7 stations. But, at 16:10 UT the same (correct) report was received from K3ZV. I mean, that 8th report at 16:10 was 2 minutes LATE, even though the transmission definitely occurred at 16:08 and was reported correctly at 16:08 by the 7 other stations. See table below. So evidently somehow, it IS possible for a transmission to be reported 2 minutes late. I wonder, does that mean it could also be reported 2 minutes early, as AF7HL's was at 13:18 (should be 13:20)?

I noticed another interesting thing. When I sort the 107 "False" decodes by receiving station callsign, I find that quite a number of receiving stations show up multiple times. More than half (58) of the "false" decodes are from receiving stations which show up with false reports more than once. Particular notable, the following reporting stations show up with at least 3 of the 107 "false" decodes each: DK6UG (8 times), K9AN (6), 4X1RF (5), GM4SFW (5), VK5MR(5), JH6LAV (3), K4COD (3), OH5RM (3), ON7KB (3), OZ1PIF (3). I know that K9AN has written his own WSPR decoder, and quite a lot of people are using it because it is said to be more sensitive than the standard WSPR decoder. IF the greater sensitivity comes at the price of a greater probability of false decodes, and IF the listed stations which seem to often generate false decodes are using the K9AN decoder, it could explain a lot of these "false" decodes. It would also be interesting to know, which WSPR decoder does AF7HL use? AF7HL does not generate ANY of the 107 listed "False" reports in September.
So, what happened to S-6? Is it still flying? If so, where? Will it turn up somewhere, soon?
Day 3 update: 26-Sep-2015
The S-6 balloon covered a huge distance overnight, and by 13:30 UT reached a groundspeed of 94 knots (108mph, 174kph). That's a speed record for these S-series balloon flights! The telemetry protocol is only designed for a maximum speed of 82 knots, after that it "wraps around" again to 0 knots. I.e. 84 knots is reported as 0, 86 knots is reported as 2 etc. So for a while the live update map was showing low speeds and it was necessary to add 84 knots to everything to see the true speed.


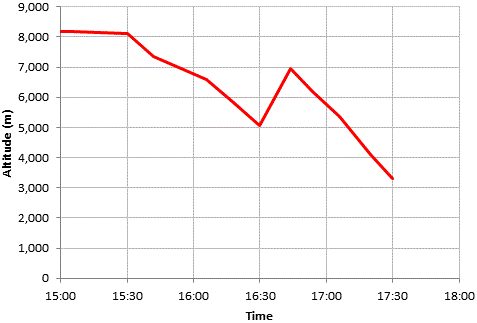 Unfortunately the balloon appears to have hit bad weather starting at about 15:30 UT and started a descent. We assume that the balloon was caught in rapid up/down air movements, and also probably moisture attached to the balloon envelope, increasing the weight and causing a loss of altitude. The last reception report was at 17:30 UT, by that time the balloon had descended to an altitude of 3,300m and slowed down to 42 knots. This chart (right) shows the altitude in the 2.5 hours from 15:00 UT to 17:30 UT. There altitude loss started from 15:30 UT but an hour later there was a rapid height gain of 2,000m in 12 minutes. Thereafter the descent continued.
Unfortunately the balloon appears to have hit bad weather starting at about 15:30 UT and started a descent. We assume that the balloon was caught in rapid up/down air movements, and also probably moisture attached to the balloon envelope, increasing the weight and causing a loss of altitude. The last reception report was at 17:30 UT, by that time the balloon had descended to an altitude of 3,300m and slowed down to 42 knots. This chart (right) shows the altitude in the 2.5 hours from 15:00 UT to 17:30 UT. There altitude loss started from 15:30 UT but an hour later there was a rapid height gain of 2,000m in 12 minutes. Thereafter the descent continued.
If the descent had continued after that at the same rate, the balloon should have continued reporting its position for at least one more hour, before landing in the sea. However, we suspect that the light was dim, due to the cloud cover at the lower altitude, and the fact that dusk was approaching (though sunset was still 1.5 hours away). The transmitter probably ran out of power and could not continue transmitting. This hypothesis is supported by the battery voltage decline in the last hour from 16:30 UT to 17:30 UT. Therefore we cannot say we tracked S-6 down to the sea; below 3,300m it had stopped transmitting and we do not know what happened thereafter.
In the following image gallery, are some weather reports/predictions that were obtained by Dave VE3KCL. Presumably an expert would be able to make sense of all those diagrams. Not I. Nevertheless they are included here for interest. On each image I have added an orange circle showing the last known position of S-6 (Latitude 47.35417 N, Longitude 29.875 W). You have to put that into context, on each weather chart. The time of the last known position report is 17:30 UT. Furthermore weather changes at different altitude. These charts are for aviation purposes. The 8,000m altitude of the S-6 balloon corresponds in aviation terms to flight level 260 (FL 260). Anyhow it certainly appears there was a lot of bad weather in the area at the time S-6 started going down.












Day 2 update: 25-Sep-2015

A nice day's flying, the balloon crossed the Eastern USA coast and headed east out across the Atlantic, picking up speed as it went!


Day 1 update: 24-Sep-2015

Dave VE3KCL managed a successful launch of balloon S-6. It climbed steadily to around 8,000m altitude and headed East, covering 245km in the 5 hours before sunset. At sunset the battery does not have enough capacity to continue powering the balloon and it shuts down until the morning. The graph (below left) shows altitude, groundspeed (knots), temperature and battery voltage. Click for larger images. The map (below right) shows the progress east from the launch site which was to the northwest of Toronto. CLICK PHOTOS for full size versions.
S-6 also was spotted on CW on the reverse beacon network, see http://www.reversebeacon.net/


Failed launch attempt: Here are two photos from an early launch attempt. It failed due to the heavy fog you can see in the photos. The fog deposited water on the balloon, weighing it down sufficiently for there to be inadequate lift to pull the payload up. Dave says: "in the frenzy of the failed launch I cut off the carbon fiber spreader section (that keep the balloons separated) to get more lift, but that did not work, and I did not replace it. That omission will give .8gm of extra lift on this ride... replacing the carbon fiber spreader would have been difficult with the rig all laced up". Dave waited some hours for the fog to clear, sun to show up, and dry out everything - before trying again.


Successful launch: The second (successful) launch attempt was also not without drama. Dave VE3KCL writes: "Today was a challenge.... our usual launch site had trees in the direction of the wind so we went travelling in the car and found a young couple building a fantastic log house and asked to use their yard for a launch... they said sure... he and she (who were constructing at the time with chop saws and other equipment) live in the basement of this 3/4-built fantastic log structure and he is a software engineer so said he would look up the S6 page... At their property, we had about 1500 feet of clear space to clear the trees so it made the launch easier."
All's well that ends well. See photos of the launch below. The first two (left) show a close-up of the balloon and the transmitter box. The three on the right show the S-6 as it disappears into the distance.





Design changes
1) a 1.2mm carbon fiber rod separating the balloon lines, to potentially protect the lower balloon from scuffing on the line to the upper balloon.
2) A new method of sealing the gas port to reduce gas leakage
3) 7 cells instead of 8 cells on the solar panel. On the S-4 flight the solar panel was running the voltage too high. As high as 4.8V which caused the protection board on the LiPo battery to take the battery out of the circuit at 4.3V. When the ambient temperature at altitude is 60C colder than on the earth, there is approximately a 20% increase in solar panel voltage. On earth the panel only charges to 3.65V so hopefully this will increase when it gets cold. It also saved a little weight.
4) A zener diode was installed to hopefully dissipate some of the energy if the voltage gets too high, and perhaps do a little heating of the electronics.
5) The flight pack is 0.5g lighter than on the S-4 and may float slightly higher (30m)
Telemetry schedule
The telemetry uses the same system as the S-4 flight. See the S-4 page for more details of the telemetry protocol. The transmission schedule for the flight is based on a 12 minute transmission cycle, commencing on the hour and repeating every 12 minutes:

Special WSPR data telemetry encodes 5th and 6th Maidenhead locator, altitude, temperature, battery voltage, ground speed, GPS status and Satellite coverage.
Photos
These photos from Dave VE3KCL show the flight payload and solar cell array. Click for larger photos.




Dave also did extensive low temperature testing of the payload, using dry ice (temperature -78C) as the coolant.



